非视距成像+卷积神经网络算法,想看哪就看哪
2020-01-31 21:00:22 来源:麦姆斯咨询 评论:0 点击:
据麦姆斯咨询报道,美国斯坦福大学和赖斯大学等机构的研究人员利用一种基于深度学习的人工智能技术打造了一款基于激光器的新型非视距成像系统,能够实时对拐角后方进行成像。
非视距成像(NLoS)可以利用从其它表面散射的光,对我们视线以外的隐藏物体进行成像,因而,利用这种成像技术可以把各种粗糙表面当作“反射镜”。
据麦姆斯咨询报道,美国斯坦福大学(Stanford University)和赖斯大学(Rice University)等机构的研究人员利用一种基于深度学习的人工智能技术打造了一款基于激光器的新型非视距成像系统,能够实时对拐角后方进行成像。相信随着进一步深入开发,该系统可以帮助自动驾驶汽车“看”到旁边车辆或繁忙十字路口周围的状况,以提前预知危险或行人。此外,它还可以安装在卫星和航天器上,捕捉小行星上洞穴内的图像。
合作研究小组负责人Christopher A. Metzler说:“与其它方案相比,我们的非视距成像系统能够提供独一无二的高分辨率和成像速度,能够实现其它方案无法想象的应用,例如在行驶中读取周边看不到的车辆车牌,甚至,读取转角后方行人佩戴的徽章等。”
Metzler及其研究团队在Optica期刊上报道称,新系统可以分辨1米外隐藏物体的亚毫米级细节。该系统针对小尺寸物体的超高分辨率成像而设计,但也可以与其它低分辨率大场景成像系统结合应用。
该研究合著者,来自普林斯顿大学(Princeton University)的Felix Heide表示:“非视距成像在医学成像、导航、机器人技术以及国防领域具有重要意义。我们的研究使这些领域的非视距成像应用迈出了坚实的一步。”
采用普通市售器件,通过深度学习解决光学难题
这项研究中的新成像系统使用了市售的相机传感器和一款强大的标准激光源(与激光笔中的激光源类似)。激光束从可见的墙壁反弹到隐藏的物体上,然后从隐藏的物体反射回墙壁,从而产生一种被称为散斑图案的干涉图案,其中编码了隐藏物体的形状。
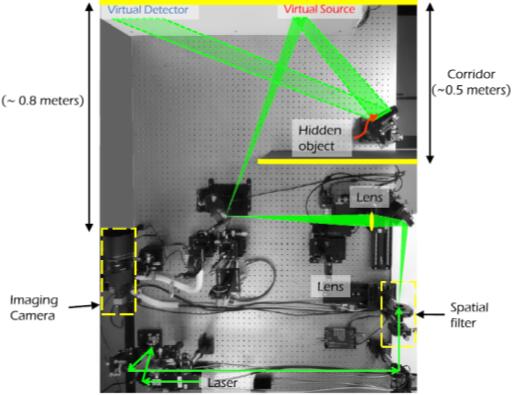
实验装置示意图。激光源发射光束,到虚拟光源,再到隐藏的物体,然后反射至虚拟探测器,最后被成像相机捕捉。
利用散斑图案重建隐藏物体的图像,面临极具挑战的计算问题。实时成像需要的短曝光时间,会带来太多的噪声,利用现有算法无法处理。为了解决这个问题,研究人员转向了深度学习。
“与其它非视距成像方案相比,我们的深度学习算法对噪声的鲁棒性更高,因此可以以更短的曝光时间运行。”该研究另一位合著者,来自南卫理公会大学(Southern Methodist University)的Prasanna Rangarajan说,“通过准确地表征噪声,我们可以合成数据以训练算法,利用深度学习解决图像重建问题,从而无需高成本地捕捉实验训练数据。”
视线转弯,见所未见
研究人员在实验中对这项新技术进行了测试,利用距墙壁约1米的成像装置,对隐藏在墙角后方的1厘米高的字母和数字进行了图像重建。使用四分之一秒的曝光时间,新技术可以获得分辨率为300微米的重建图像。
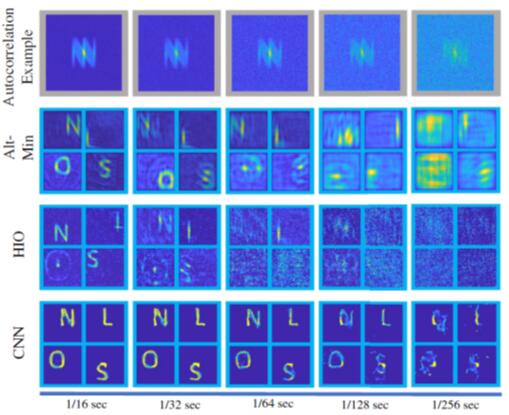
不同曝光时长的模拟和重建实验。基于卷积神经网络(Convolutional neural networks, CNN)的新方案对噪声的鲁棒性更强,相比基于混合输入输出(Hybrid input–output, HIO)或交替最小化(Alternating minimization, Alt-Min)等传统相位恢复(Phase retrieval, PR)算法的系统,能够在更少的光量下工作,从而实现更高的帧速率。
这项研究是美国国防高级研究计划局(DARPA)REVEAL项目的一部分,该项目旨在利用主动光场技术革命性地提高可视能力,目前正在开发各种不同的技术方案来对拐角后方的隐藏物体进行成像。目前,研究人员正在努力扩展视场,使其能够对更大尺寸的物体进行重建图像,使系统更具实用性。
延伸阅读:
上一篇:SiOnyx发布新款高清彩色夜视相机SiOnyx Pro
下一篇:FLIR推出首款用于甲烷检测的非制冷型固定式互联热像仪